SenseNova-U1-8B 统一多模态模型实测:单卡 H20 跑通端到端图像生成
商汤 2026 年 4 月开源的 NEO-Unify 架构统一多模态模型,在 H20 上的完整部署 + 13 个测试用例 + 性能数据 + 横向对比。

前言
SenseNova-U1 是商汤科技 2026 年 4 月底开源的统一多模态模型家族,基于全新的 NEO-Unify 架构。与传统 Diffusion 模型(需要 UNet/DiT + VAE + Text Encoder 多组件管线)不同,U1 在架构层面做了一个激进的选择:完全去除视觉编码器(VE)和变分自编码器(VAE),在一个纯 Transformer 架构内同时完成多模态理解与生成。
这意味着:文字理解、图像理解、图像生成、图像编辑、交错生成(图文混排)——全部在同一个 8B 参数的模型里完成,不需要拼接多个组件。
本文记录了在 NVIDIA H20 (144GB) 单卡上部署 SenseNova-U1-8B-MoT-Infographic(信息图增强版)的完整过程,并从多个维度做了系统性测试。
模型架构与能力
核心架构:NEO-Unify
NEO-Unify 架构的三个关键特性:
- 端到端统一建模 —— 语言和视觉信息在同一个模型中作为统一复合体建模
- 像素级保真度 —— 在保持语义丰富性的同时维持像素级视觉保真度
- 原生 MoT(Mixture of Tokens) —— 通过原生混合 Token 机制高效跨模态推理,最小化模态冲突
模型家族
| 模型 | 参数量 | 特点 |
|---|---|---|
| U1-8B-MoT | 8B | 密集主干,基础版 |
| U1-8B-MoT-SFT | 8B | 经过统一 SFT 训练 |
| U1-8B-MoT-Infographic | 8B | 信息图增强版(本文测试) |
| U1-A3B-MoT | A3B | MoE 主干,更小更快 |
注:8B-MoT 中的 8B 指 ~8B 理解参数 + ~8B 生成参数,通过 MoT 机制共享。
完整能力矩阵
| 能力 | 说明 | 当前版本支持 |
|---|---|---|
| 文生图(通用) | 自然场景、人物、风景、艺术风格 | ✅ |
| 文生图(推理) | 理解物理规律、因果关系后生成 | ✅ |
| 文生图(信息图) | 海报、图表、简历、漫画等高密度内容 | ✅(增强) |
| 图像编辑(通用) | 修改颜色、添加/删除物体、风格变换 | ✅ |
| 图像编辑(推理) | 理解时间变化、物理变化后编辑 | ✅ |
| 交错图文生成 | 生成图文混排内容(教程、故事) | ✅(Beta) |
| 视觉理解 / VQA | 图像问答、文档理解 | ✅ |
| VLA(视觉语言动作) | 机器人控制 | ✅ |
| 世界建模 | 物理世界模拟 | ✅ |
Infographic 版本特别优化
本文测试的 MoT-Infographic 版本相比基础版的提升:
| 基准 | 基础版 | Infographic 版 | 提升 |
|---|---|---|---|
| BizGenEval (hard) | 39.8 | 46.6 | +6.8 |
| BizGenEval (easy) | 61.1 | 65.4 | +4.3 |
| IGenBench Q-ACC | 51.3 | 69.5 | +18.2 |
| IGenBench I-ACC | 4.2 | 17.0 | +12.8 |
RL 阶段专门优化了信息图生成中的黑色背景问题,并增强了文字渲染能力。
硬件环境
- GPU: NVIDIA H20 144GB(单卡)
- 系统: Ubuntu / CUDA 12.8
- Python: 3.11
- PyTorch: 2.8.0+cu128
- 显存占用: ~35 GB(BF16 推理)
部署步骤
1. 创建独立 Conda 环境
为避免污染已有的推理服务环境(重要),在数据盘单开一个:
conda create -p /data/envs/u1 python=3.11 -y
conda activate /data/envs/u12. 安装依赖
SenseNova-U1 的核心依赖非常干净。关键技巧是用 --no-deps 装 PyTorch,避免拉 2GB+ 的 nvidia 包(改用 LD_LIBRARY_PATH 引用已有库):
pip install torch==2.8.0 torchvision==0.23.0 --no-deps
pip install transformers==4.57.1 tokenizers==0.22.1 \
accelerate==1.10.1 huggingface-hub==0.36.2 \
safetensors==0.6.2 sentencepiece==0.2.1 \
pillow tqdm packaging httpx typing_extensions filelock3. 安装模型代码包
git clone --depth 1 https://github.com/OpenSenseNova/SenseNova-U1.git /data/SenseNova-U1
pip install -e /data/SenseNova-U1 --no-deps4. CUDA 库配置
由于 --no-deps 跳过了 nvidia 包,需要把 LD_LIBRARY_PATH 指向任意已有 PyTorch 环境里的 site-packages/nvidia/*/lib:
# 示意:把下面 $EXISTING_ENV 换成任何一个已经装了完整 nvidia/* 的 conda 环境
EXISTING_ENV=/path/to/another-env
export LD_LIBRARY_PATH=\
$EXISTING_ENV/lib/python3.10/site-packages/nvidia/cudnn/lib:\
$EXISTING_ENV/lib/python3.10/site-packages/nvidia/cuda_nvrtc/lib:\
$EXISTING_ENV/lib/python3.10/site-packages/nvidia/cublas/lib:\
$EXISTING_ENV/lib/python3.10/site-packages/nvidia/cuda_runtime/lib:\
$EXISTING_ENV/lib/python3.10/site-packages/nvidia/cufft/lib:\
$EXISTING_ENV/lib/python3.10/site-packages/nvidia/cusolver/lib:\
$EXISTING_ENV/lib/python3.10/site-packages/nvidia/cusparse/lib:\
$EXISTING_ENV/lib/python3.10/site-packages/nvidia/cusparselt/lib:\
$EXISTING_ENV/lib/python3.10/site-packages/nvidia/nccl/lib:\
/usr/local/cuda-12.8/lib645. 推理测试
CUDA_VISIBLE_DEVICES=7 python /data/SenseNova-U1/examples/t2i/inference.py \
--model_path /data/models/SenseNova-U1-8B-MoT-Infographic \
--prompt "A cute cat sitting on a windowsill" \
--output /data/test_output.png \
--num_steps 50 \
--cfg_scale 4.0模型加载约 1 秒(8 个 safetensors 分片),推理生成约 78 秒,输出 2048×2048 RGB PNG。
6. API 服务封装
vLLM / SGLang 暂不支持 NEO-Unify 架构,所以用 FastAPI 封装了一层 OpenAI 兼容的图片生成 API:
@app.post("/v1/images/generations")
def generate_image(req: GenerateRequest):
images = engine.generate(
prompt=req.prompt,
width=req.width, height=req.height,
cfg_scale=req.cfg_scale,
num_steps=req.num_steps,
seed=seed,
)
return GenerateResponse(created=timestamp, data=[ImageData(b64_json=b64)])启动:
CUDA_VISIBLE_DEVICES=7 bash start_u1_api.sh # 监听 0.0.0.0:80017. Nginx 反向代理
通过已有的 nginx 网关把服务暴露出去:
location /u1/ {
rewrite ^/u1/(.*) /$1 break;
proxy_pass http://<内网API主机>:8001;
proxy_read_timeout 600;
}最终访问路径:https://your-api-host/u1/v1/images/generations
全场景测试报告
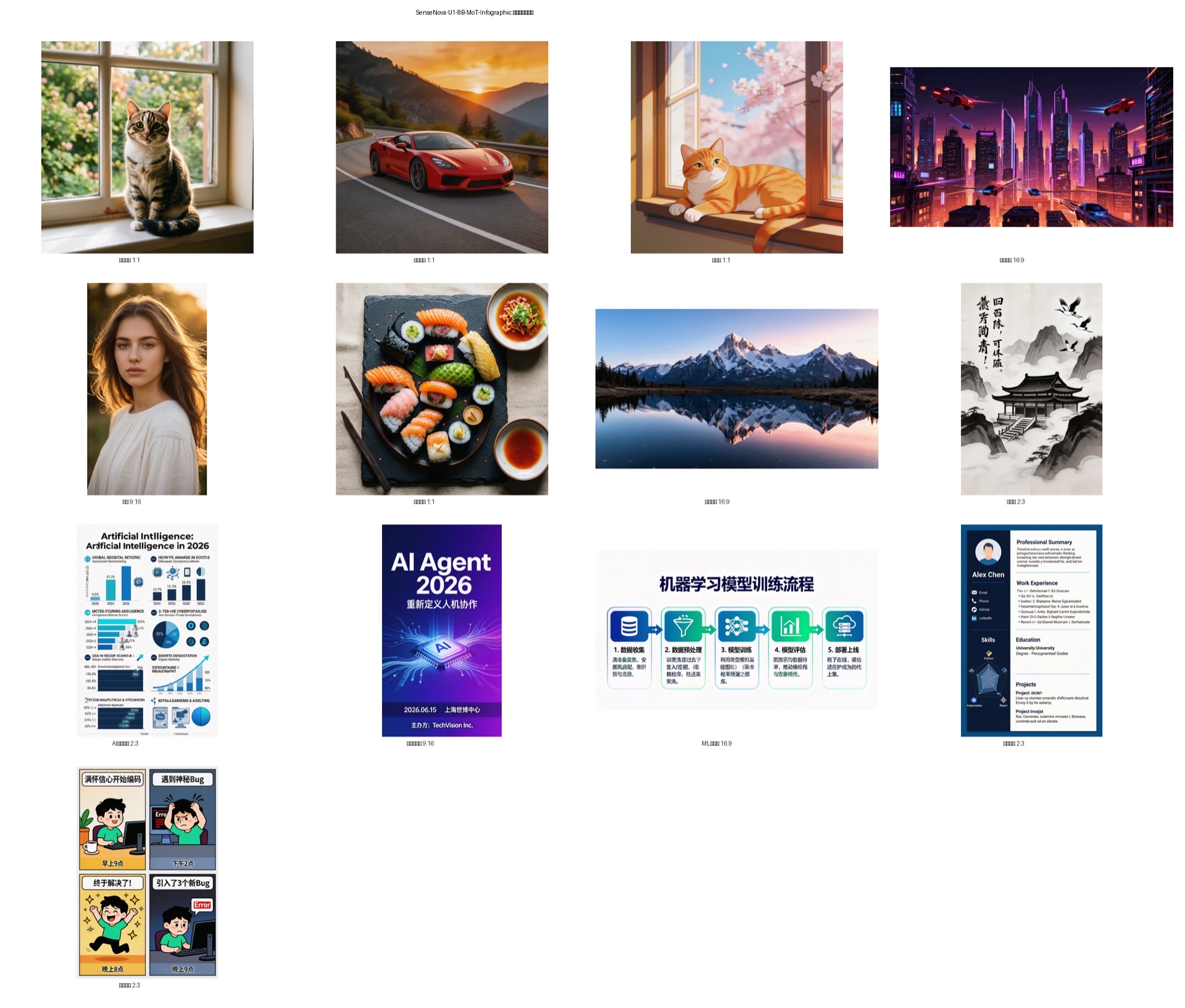
测试一:通用文生图
基础图像生成能力测试,覆盖不同题材和风格。
1.1 自然摄影风格
| 测试 | Prompt | 分辨率 | 耗时 |
|---|---|---|---|
| 窗台小猫 | A cute cat sitting on a windowsill | 2048×2048 | 78s |
| 跑车夕阳 | A red sports car on a mountain road at sunset | 2048×2048 | 77.9s |
| 白猫沙发 | A white cat sleeping on a blue sofa | 2048×2048 | 77.8s |
| 霓虹城市 | A futuristic city skyline at night with neon lights | 2048×2048 | 77.6s |


评价:基础文生图质量出色,2048×2048 原生分辨率下细节丰富,色彩饱满,光影自然。
1.2 多宽高比测试
| 测试 | Prompt | 宽高比 | 分辨率 | 耗时 |
|---|---|---|---|---|
| 赛博城市 | A cyberpunk cityscape with flying cars… | 16:9 | 2720×1536 | ~78s |
| 人像摄影 | A young woman with flowing hair… | 9:16 | 1536×2720 | ~78s |
| 水墨山水 | 中国传统水墨画,远山近水… | 2:3 | 1664×2496 | ~78s |
| 美食摄影 | Professional food photography of sushi… | 1:1 | 2048×2048 | ~78s |
| 山水风光 | Mountain lake at sunrise, golden light… | 16:9 | 2720×1536 | ~78s |





评价:模型原生支持多种宽高比,无论横版还是竖版构图都很自然,没有明显拉伸或裁切痕迹。
1.3 艺术风格测试
| 测试 | Prompt | 风格 |
|---|---|---|
| 动漫橘猫 | Anime style orange tabby cat… | 日系动漫 |
| 水墨画 | 中国传统水墨画,远山近水… | 国画水墨(见 1.2) |

评价:风格迁移能力强,无论写实摄影、动漫还是传统国画风格都能准确表达。
测试二:信息图生成(模型特长)
这是 Infographic 版本的核心能力 —— 生成高密度、结构化的视觉内容。
2.1 活动海报
Prompt: 设计一张科技公司产品发布会海报。标题 “AI Agent 2026” 使用大号白色无衬线字体居中,副标题 “重新定义人机协作”。背景使用深蓝到紫色的渐变,中央有一个发光的 AI 芯片图标 …

结果分析:
- ✅ 标题 “AI Agent 2026” 渲染清晰准确,字体选择合理
- ✅ 副标题 “重新定义人机协作” 中文渲染正确
- ✅ 深蓝-紫色渐变背景精美
- ✅ AI 芯片图标设计感强,发光效果到位
- ✅ 底部信息栏(日期、地点、主办方)排版规整
- ✅ 整体构图专业,可直接用于实际宣传
评分:9/10 —— 文字渲染准确率极高,设计感强,几乎可以直接商用。
2.2 知识流程图
Prompt: 创建一张”机器学习模型训练流程”知识图解。采用流程图布局,从左到右依次展示五个步骤:1.数据收集 2.数据预处理 3.模型训练 4.模型评估 5.部署上线 …
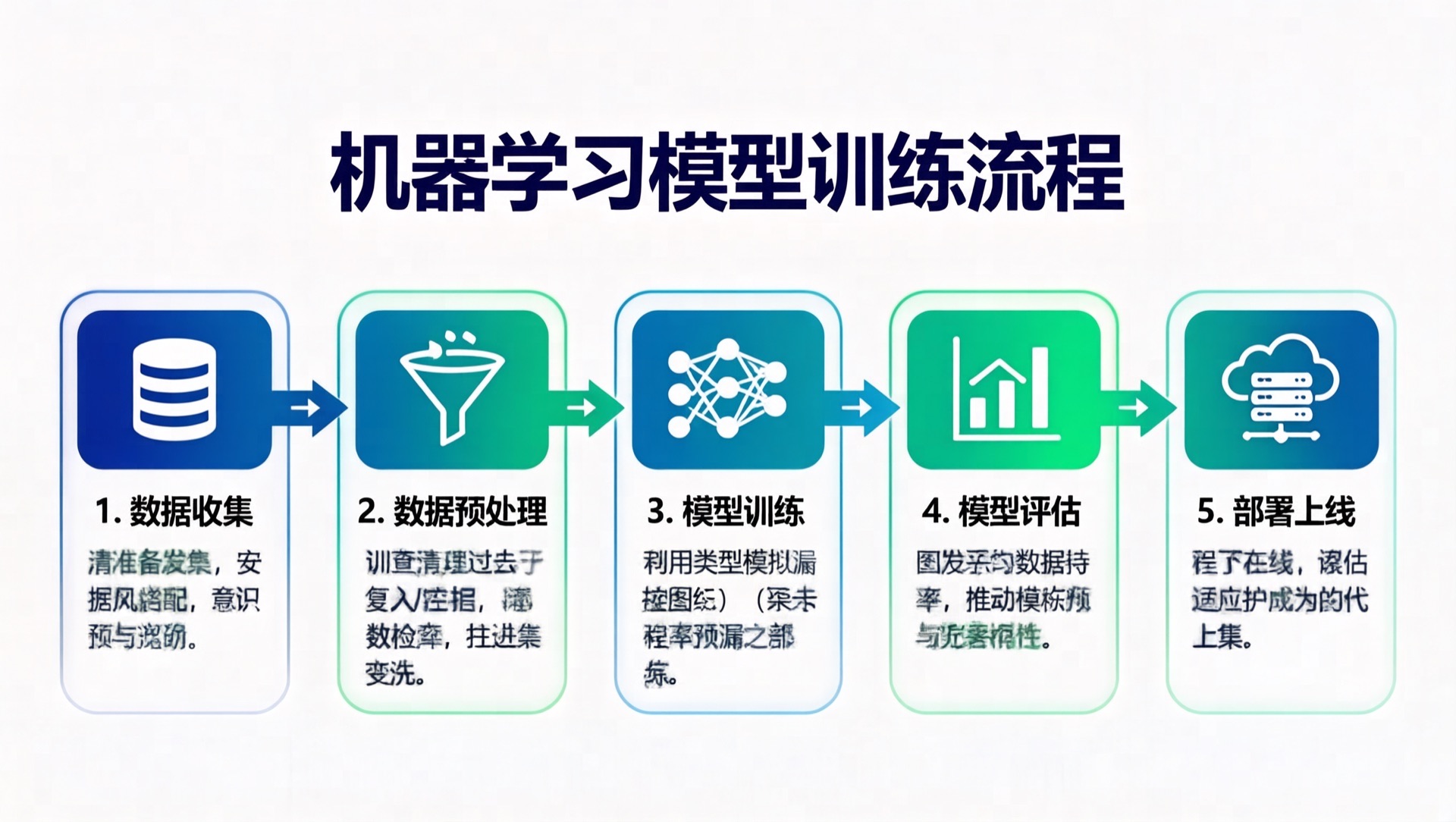
结果分析:
- ✅ 标题 “机器学习模型训练流程” 渲染正确
- ✅ 5 个步骤圆角矩形布局清晰
- ✅ 步骤间箭头连接逻辑正确
- ✅ 每个步骤配有对应图标(数据库、漏斗、神经网络、图表、云)
- ✅ 蓝绿色主题配色协调
- ⚠️ 步骤下方说明文字部分出现语义漂移(已知限制)
评分:8/10 —— 结构和视觉设计优秀,大标题和步骤名渲染准确,细节文字有少量 hallucination。
2.3 简历 / CV 设计
Prompt: Design an infographic resume for a software engineer. Left sidebar (dark navy) with avatar, name “Alex Chen”, contact icons, skills radar chart. Main content with sections …

结果分析:
- ✅ 整体布局完全符合要求:左侧深色边栏 + 右侧白色主内容区
- ✅ “Alex Chen” 名字渲染正确
- ✅ 联系方式图标(Email、Phone、GitHub、LinkedIn)全部正确
- ✅ 技能雷达图(Python、Go、React、Kubernetes)准确
- ✅ 分段结构清晰(Summary / Experience / Education / Projects)
- ⚠️ 正文出现 lorem ipsum 式填充文字(小字密集区域的已知限制)
评分:8/10 —— 版式专业,标题和关键词渲染准确,适合做简历模板视觉稿。
2.4 四格漫画
Prompt: 创建一张四格漫画风格的信息图,主题是”程序员的一天”。四格竖向排列 …

结果分析:
- ✅ 四格布局完美,每格独立成画
- ✅ 角色设计一致性极佳(同一个程序员形象贯穿四格)
- ✅ 标题文字全部正确:“满怀信心开始编码”、“遇到神秘 Bug”、“终于解决了!”、“引入了 3 个新 Bug”
- ✅ 时间标注正确:“早上 9 点”、“下午 2 点”、“晚上 8 点”、“晚上 9 点”
- ✅ 表情变化生动:自信 → 抓狂 → 狂喜 → 沮丧
- ✅ 屏幕上 “Error” 文字渲染正确
- ✅ 色彩和氛围随剧情变化(明亮 → 红色警告 → 金色庆祝 → 暗色)
评分:9.5/10 —— 这是测试中最惊艳的结果。叙事完整、角色一致、文字全部正确、情绪表达到位。
2.5 数据可视化图表
Prompt: 信息图标题 “2026 AI 发展趋势”,包含柱状图展示各领域增长率 …
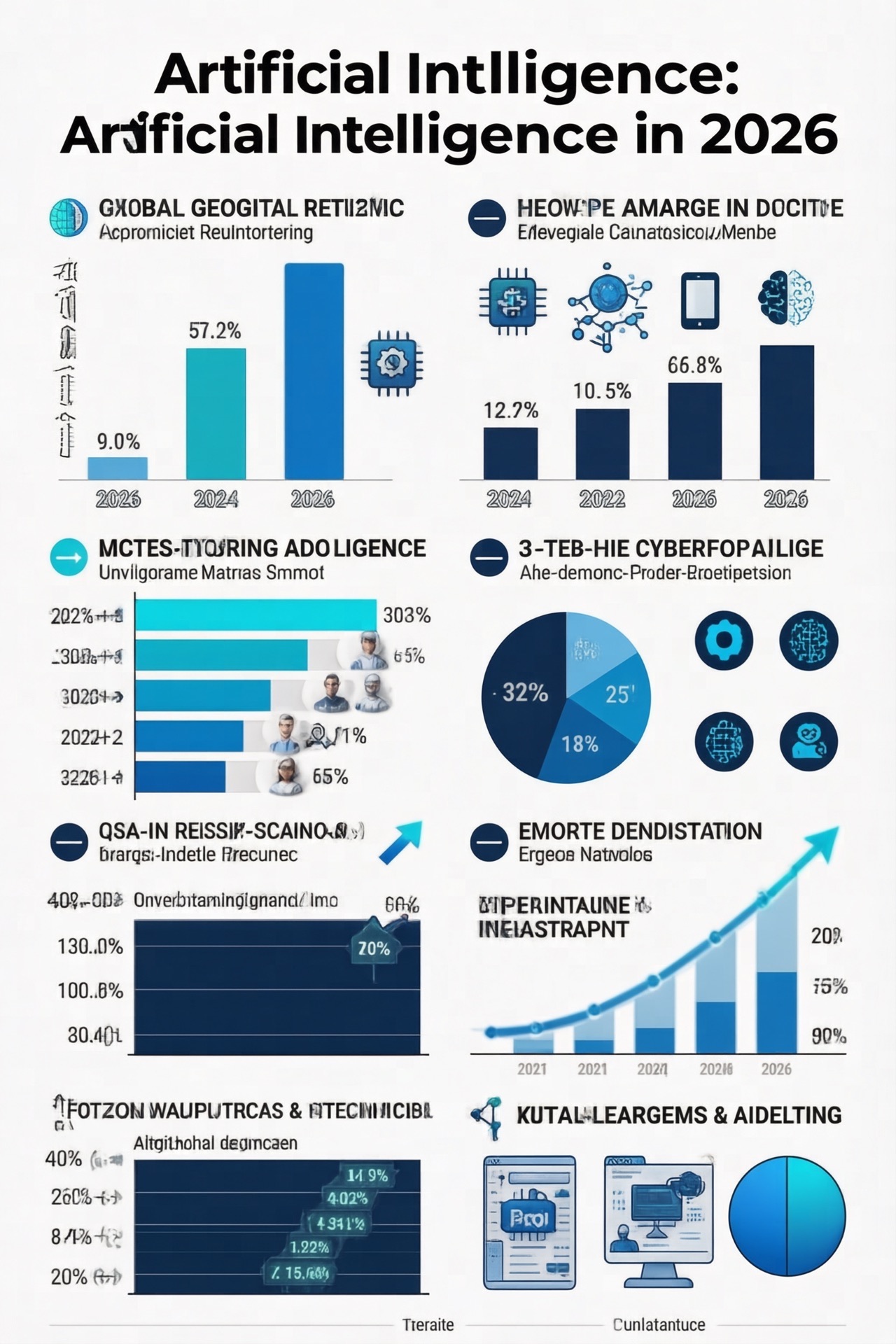
结果分析:
- ✅ 标题和图例渲染正确
- ✅ 整体信息图布局合理
- ⚠️ 图表数值与 prompt 存在偏差(纯生成模型的固有限制)
评分:7/10 —— 视觉效果好但数据精确度无法保证。适合概念展示,不适合精确数据呈现。
测试三:中文渲染能力
| 测试内容 | 渲染准确度 |
|---|---|
| 短标题(2–6 字) | ✅ 极高 |
| 中等标题(8–12 字) | ✅ 高 |
| 段落正文(20 字+) | ⚠️ 有偶发错误 |
| 数字+中文混合 | ✅ 高 |
| 英文短语 | ✅ 极高 |
结论:标题和关键词级别的中文渲染已达到商用水准,长段落文字仍有改进空间。
性能数据
基准测试
2048×2048 分辨率、50 步采样、CFG=4.0 条件下:
| 指标 | 数值 |
|---|---|
| 单张生成耗时 | ~78 秒 |
| 三次测试标准差 | < 0.2 秒 |
| 显存占用 | ~35 GB |
| 模型加载时间 | ~1 秒 |
不同配置预估
| 分辨率 | 步数 | 预估耗时 |
|---|---|---|
| 2048×2048 | 50 | ~78s |
| 2048×2048 | 28 | ~44s |
| 1024×1024 | 50 | ~20s |
| 1024×1024 | 28 | ~11s |
注:官方有 8-step 蒸馏版本(LoRA),可将步数降至 8,大幅提速。
与其他模型对比
| 特性 | SenseNova-U1 | DALL·E 3 | Stable Diffusion 3 | Midjourney |
|---|---|---|---|---|
| 架构 | 纯 Transformer | Transformer+Diffusion | DiT+VAE | 未公开 |
| 参数量 | 8B | 未公开 | 2B+ | 未公开 |
| 开源 | ✅ | ❌ | ✅ | ❌ |
| 理解+生成统一 | ✅ | ❌ | ❌ | ❌ |
| 图像编辑 | ✅(同一模型) | ✅(独立) | ✅(独立) | ❌ |
| 文字渲染 | 优秀 | 优秀 | 一般 | 一般 |
| 信息图生成 | 优秀 | 一般 | 差 | 一般 |
| 自部署 | ✅ 单卡可跑 | ❌ | ✅ | ❌ |
使用体验总结
优点
- 架构创新 —— 首个完全去除 VE 和 VAE 的统一多模态模型,理解和生成在同一模型中完成
- 信息图生成能力突出 —— 海报、流程图、漫画、简历等结构化内容质量高
- 文字渲染优秀 —— 中英文标题级渲染准确率极高,远超传统 Diffusion 模型
- 部署简单 —— 纯 Python 环境、无需编译 CUDA 算子、单卡 35 GB 显存
- 多宽高比原生支持 —— 1:1、16:9、9:16、2:3 等无需裁切
- 开源友好 —— Apache 2.0 许可证,支持商用
不足
- 推理速度偏慢 —— 单卡 78 秒/张(2K),不适合实时交互场景
- vLLM / SGLang 不支持 —— 自定义架构暂无法使用主流推理框架加速
- 密集正文仍有挑战 —— 长段落小字体文字渲染偶有错误
- 无批量并行 —— 单请求阻塞式推理,不支持 continuous batching
- 图像编辑需额外脚本 —— API 封装目前仅覆盖 T2I,编辑功能需走命令行
适用场景
| 场景 | 适合度 | 说明 |
|---|---|---|
| 营销海报 / Banner | ⭐⭐⭐⭐⭐ | 核心优势,文字渲染准确 |
| 知识科普图 | ⭐⭐⭐⭐ | 流程图、对比图效果好 |
| 漫画 / 故事板 | ⭐⭐⭐⭐⭐ | 角色一致性出色 |
| 简历 / PPT 配图 | ⭐⭐⭐⭐ | 版式设计专业 |
| 数据图表 | ⭐⭐⭐ | 视觉好但数值不精确 |
| 实时生成 | ⭐⭐ | 速度瓶颈,需蒸馏版 |
| 精确数据可视化 | ⭐⭐ | 建议用专业绘图库 |
API 调用示例
curl -X POST https://your-api-host/u1/v1/images/generations \
-H "Content-Type: application/json" \
-d '{
"prompt": "设计一张简约风格的产品发布海报,标题\"新品上市\",蓝色渐变背景",
"width": 1536,
"height": 2720,
"num_steps": 50,
"cfg_scale": 4.0,
"seed": 42
}'返回格式:
{
"created": 1716500000,
"data": [
{
"b64_json": "/9j/4AAQ...(base64 编码的 PNG)...",
"revised_prompt": "..."
}
]
}LiteLLM 集成配置
model_list:
- model_name: sensenova-u1
litellm_params:
model: openai/sensenova-u1
api_base: https://your-api-host/u1
api_key: "sk-placeholder"
model_info:
mode: image_generation总结
SenseNova-U1 代表了多模态 AI 的一个重要方向 —— 从”模态适配”走向”真正统一”。8B 参数量在保持可控部署成本(单卡 H20 即可运行)的同时,在信息图生成领域达到了开源 SOTA 水平。
Infographic 版本的核心价值在于:它不只能生成漂亮的图片,更能生成 有结构、有信息、有文字 的视觉内容。这在内容创作、营销设计、教育科普等场景里是真正的实用价值。
对于需要批量生成海报、科普图解、漫画内容的团队,这是目前最值得关注的开源自部署方案之一。
部署环境:NVIDIA H20 144GB × 1 | Ubuntu | CUDA 12.8 | PyTorch 2.8.0 模型版本:SenseNova-U1-8B-MoT-Infographic 测试日期:2026 年 5 月